
#wannabeeeeeee the best DataScientist
Python_Pandas 본문
728x90
◎ Python_Pandas
- pandas는 "python data analysis"의 약자입니다.
- pandas는 정형 데이터 처리에 특화되어 있다.
- pandas가 Excel에 비해 고성능 데이터 처리에 적합하다.
§ 백문이 불여일견이라
※ Pandas의 기본 자료구조
# pandas 라이브러리를 불러옵니다. pd를 약칭으로 사용합니다.
import pandas as pd
s = pd.Series([1,3,5,np.nan,6,8]) # s는 1, 3, 5, np.nan, 6, 8을 원소로 가지는 pandas.Series
dates = pd.date_range('20210101',periods=6) # 20210101부터 6일간의 날짜 범위를 생성하는 함수
# 6x4 행렬에 -1에서 1 사이의 랜덤한 숫자를 가지는 원소를 가지고, index열은 dates, 나머지 coulmns은 순서대로 A, B, C, D로 하는 DataFrame 생성
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=['A','B','C','D'])


※ Dataframe 기초 method
df.head() # dataframe의 맨 위에서 다섯줄을 보여주는 head()
df.tail() # dataframe의 맨 뒤에서 다섯줄을 보여주는 head()
df.index # dataframe index
df.columns # dataframe columns
df.values # dataframe values
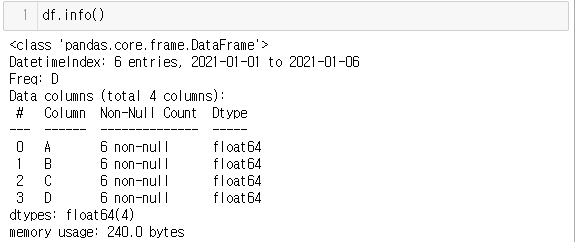
df.info() # dataframe에 대한 전체적인 요약정보를 보여주는 함수
df.describe() # dataframe에 대한 전체적인 통계정보를 보여주는 함수
df.sort_values(by='B') # column B를 기준으로 오름차순 정렬
df.sort_values(by='B',ascending=False) # column B를 기준으로 내림차순 정렬



※ DataFrame Indexing
df["A"] # column을 찾아서 인덱싱한다 == dictionary의 인덱싱과 같다.
df.loc['2021-01-01'] # index를 찾아서 인덱싱할 땐 loc 사용
df.iloc[0,2] # dataframe 에서는 1행 2열로 인식한다.
df.values[0,2] # df.iloc[0,2]와 동일한 값을 가진다.
df.iloc[2] # df 3열을 불러온다.
df[:3] # df 1~3열을 불러온다.
df['2021-01-02':'2021-01-04'] # 02~04일까지의 행에 해당하는 모든 열 반환, row는 슬라이싱 가능
# column 슬라이싱은 되지 않는다. df["A":"C"] (X) df[["A","B","C"]] (O)
df.iloc[:,1] # 모든 행에 대한 1열만 반환
df.iloc[1,[0,2]] # 2행 1열, 2행 3열 값 반환


※ Fancy Indexing
# pandas는 fancy indexing을 지원합니다.
df[df.A > 0]["A"].values # column A에 있는 원소들중에 0보다 큰 데이터를 가져옵니다.
df.loc[df.A > 0,"A"] # df[df.A > 0]["A"].values와 같은 값 반환
df.iloc[df.A > 0,0] # iloc는 불리언 마스크를 지원하지 않는다!!
df[df > 0]
df2=df.copy() # dataframe 하나를 복사합니다. 정말 말그대로 복사합니다.
# df에 ['one', 'one','two','three','four','three'] 리스트를 column의 value로 하는 column E를 추가합니다.
df2['E']=['one', 'one','two','three','four','three'] #E가 존재하면 update
df2['E'].isin(['two','four']) # df.isin은 해당 value들이 들어있는 row에 대해선 True를 가지는 Series를 리턴한다.


※ 외부 데이터 읽고 쓰기
# data 폴더에 있는 iris.csv를 불러오자.
data= pd.read_csv("../data/iris.csv",encoding="utf-8")
############### 중요한 tip #############################
# Mac을 쓰는 경우 encoding="utf-8"이 필요없지만 window를 쓰는 경우 필요합니다.
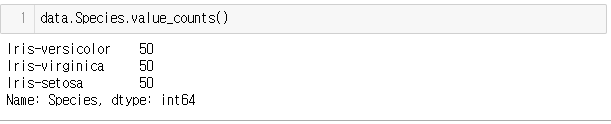
data.Species.value_counts() # Species column의 종류와 개수를 파악하는 함수
# 중복되지 않는 column의 값을 보고 싶을때
data.Species.unique() # method 1
set(data["Species"]) # method 2
# Species column을 숫자로 바꿔보자.
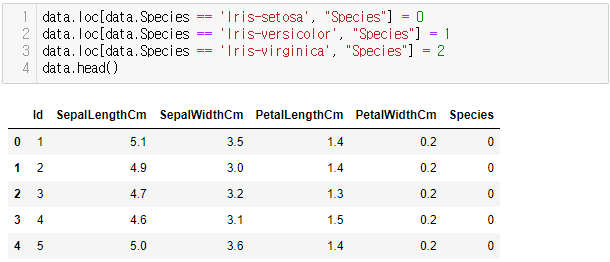
data.loc[data.Species == 'Iris-setosa', "Species"] = 0
data.loc[data.Species == 'Iris-versicolor', "Species"] = 1
data.loc[data.Species == 'Iris-virginica', "Species"] = 2
# 바꾼 Dataframe을 Iris_edited.csv 로 저장하자.
data.to_csv("../data/Iris_edited.csv") # 저장할 때는 encoding="utf-8"가 필요하지 않습니다.


728x90
'Data scientist > PYTHON' 카테고리의 다른 글
| Python_Crawling (0) | 2021.07.30 |
|---|---|
| Python_Seaborn (0) | 2021.07.29 |
| Python_Numpy (0) | 2021.07.27 |
| Python_데이터 입출력(IO) (0) | 2021.07.23 |
| Python_function() (0) | 2021.07.22 |
'Data scientist/PYTHON' Related Articles
more



