◎ Long Short-Term Memory (LSTM)
- Vanilla RNN을 개선한 LSTM 구조
- 기억할 것은 오래 기억하고, 잊을 것은 빨리 잊어버리는 능력이 있다.
- 단점 : 학습 매개변수가 많고 학습 노하우가 중요

※ Cell State - 기억을 오랫동안 유지할 수 있는 구조, 새로운 특징을 덧셈으로 받는 구조(Residual Network)
+ RNN과 달리 Cell State가 있어서 '기억'에 관한 부분을 전담한다.
※ Hidden State - 계층의 출력/다음 타임 스텝으로 넘기는 정보
※ Forget Gate - Sigmoid 활성 함수로, 0~1의 출력 값을 가짐, Cell state에 이를 곱해 주어서 '얼만큼 잊은지'를 결정
※ Input Gate - Sigmoid 활성 함수로, 0~1의 출력 값을 가짐, 새롭게 추출한 특징을 얼만큼 사용할 지 결정
※ Output Gate - igmoid 활성 함수로, 0~1의 출력 값을 가짐, Cell로부터 출력을 얼마나 내보낼지 결정하는 역할
◎ GRU (Gated Recurrent Unit)
- Cell State가 없고, Hidden State만 존재
- Forget Gate와 Input Gate를 결합
- Reset Gate 추가

※ Forget Gate를 1에서 빼서 Input Gate로 사용
※ Reset Gate : Sigmoid 활성 함수로, 이전 Hidden state를 얼마나 사용할지 정하는 역할, 0에 가까운 값이 되면 'Rest'이 된다. + Reset 된 특징은 현재 time step부터 Fully-connected layer 입력에서 제외된다.
※ Hidden state : Reset gate, Forget gate를 모두 적용하여 Hidden state를 계산한다. LSTM의 Cell state와 Hidden state 역할을 모두 겸한다.
◎ 배치 정규화 (Batch Normalization)
- 학습 과정에서 계층별로 입력의 데이터 분포가 달라지는 현상을 Internal Covariate Shift라고 한다.
- 각 배치별로 평균과 분산을 이용해 정규화하는 계층을 배치 정규화 계층이라 한다.

○ 정규화로 인해, 모든 계층의 Feature가 동일한 Scale이 되어 학습률 결정에 유리하다.
○ 추가적인 Scale, Bias를 학습하여 Activation에 적합한 분포로 변환할 수 있다.

※ 합성곱 계층에 적용할 경우, 채널 별로 정규화한다. 즉, 배치, 높이, 너비에 대해 평균과 분산을 계산한다.
◎ Inception Network
(a) Inception module
- 다양한 크기의 합성곱 계층을 한번에 계산하는 Inception module

(b) Inception module with dimension reductions
- 연산량을 줄이기 위한 1X1 합성곱 계층, 이러한 구조를 Bottleneck 구조라고 부른다.
- Bottleneck 구조의 활용으로, Receptive field를 유지하면서 파라미터의 수와 연산량을 줄일 수 있다.
- 역전파에서 기울기 소실이 발생하는 것을 방지하기 위해, 같은 문제를 여러 단계에서 풀도록 한다.

◎ Residual Network
- 딥러닝 연구에 아주 큰 한 획을 그은 ResNet의 구조
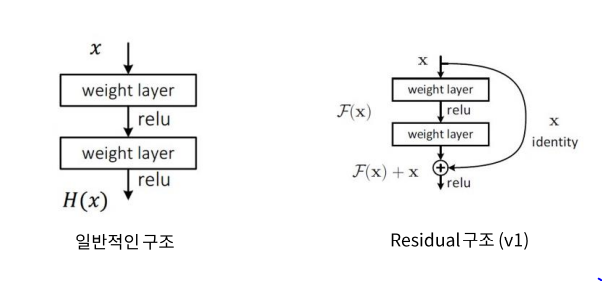
※ Skip Connection은 Feature를 추출하기 전 후를 더하는 특징, 일반 구조(왼쪽)에서 표현 가능한 것은 Residual 구조(오른쪽)에서도 표현 가능하다.

※ 한 단위의 특징 맵을 추출하고 난 후에도 활성 함수를 적용하는 것이 상식이었다. 하지만 개선된 구조에서는 Identity Mapping을 얻기 위해서 Pre-Activation을 제안했다.
◎ DenseNet
- ResNet의 아이디어를 계승하여 좋은 성능을 끌어낸 DenseNet
- Dense Block을 제안한다. Dense Block 내에서는 ResNet과 같이 Pre-Activation 구조를 사용한다.

※ Dense Block : 이전 특징 맵에 누적해서 Concatenate하는 결과
※ 레이어가 깊어지면서 연산량이 급격히 증가하는 것을 막기 위해, 1X1 Conv를 이용한 Bottleneck Layer를 사용
◎ 전이 학습 (Transfer Learning)

※ 전이 학습의 장점 : Dataset 부족의 해결, 비용 절감, 학습에 필요한 인력 감소
◎ Fine-Tuning

※ 일반적으로 Knowledge Transfer해 온 계층들은 Freeze 시켜서 학습하지 않고, 새로운 계층만 학습을 한다. 단, 학습 데이터셋이 충분히 큰 경우에는 모든 계층을 학습해도 좋다.
'Data scientist > Deep Learning' 카테고리의 다른 글
| Deep Learning_2 (0) | 2021.09.16 |
|---|---|
| Deep Learning_1 (0) | 2021.09.15 |