728x90
※ What we need : 텍스트를 입력으로 받아 원하는 항목에 대한 수치를 출력하는 것(e.g. 감성 분석, 주제 분류)
※ What we need to do : 문장을 latent space에 projection 하여 decision boundary를 찾는 것
※ In Probabilistic Perspective : 문장이 주어졌을 때, 문장이 속할 클래스의 확률 분포 함수를 approximate

◎ Text Classification using RNN

○ Bidirectional Multi-layered RNN
- Non-autoregressive task이므로 입력을 한번에한 번에 받게 된다. 따라서 모든 time-step을 한 번에 병렬로 처리 가능
☆ Feed-forward 과정
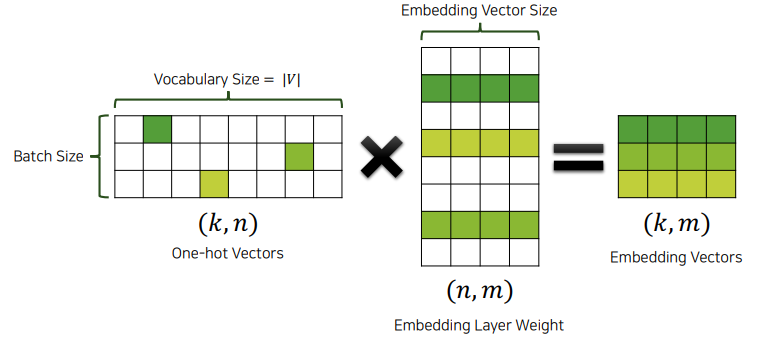
- One-hot vector를 입력으로 받아 embedding layer에 넣어준다.
- Embedding vector를 RNN에 넣어 출력을 얻는다.
- RNN의 출력값 중 마지막 time-step의 값을 잘라낸다.
- 잘라낸 값을 softmax layer에 통과시켜 각 클래스별 확률 값을 얻는다.

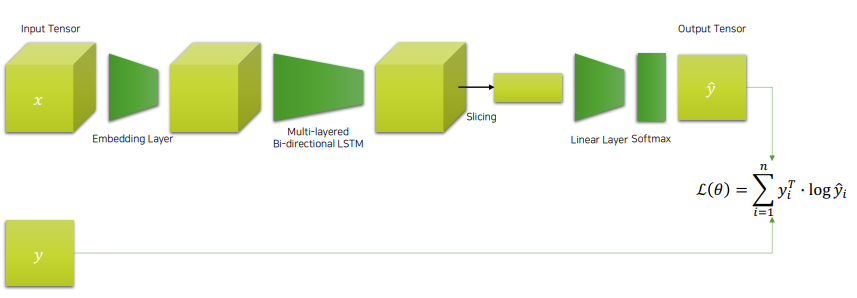
○ Architecture
- Embedding Layer -> LSTM -> Linear Layer -> Softmax
◎ Text Classification using CNN
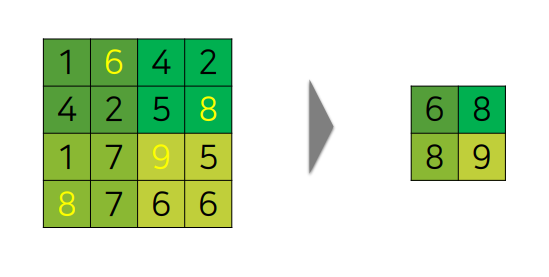
○ Down sampling 기법 : Max-pooling
○ Motivations
- 감성 분석(sentiment analysis)
- 클래스를 결정하는 일부 문구의 패턴이 있기 마련
- 이때, 문구 내의 단어들을 비슷한 의미의 단어들로 치환할 수 있을 것
- 비슷한 의미의 문구의 임베딩 벡터의 패턴을 인식할 수 있게 하는것이 CNN
○ Summary of CNN
- RNN에 비해 좀 더 직관적인 방법
- RNN은 문장의 문맥을 이해한다면, CNN은 문장 내 단어의 패턴을 인식
- Embedding layer에 one-hot vector를 넣어주어 구현할 것
728x90
'Data scientist > 자연어처리' 카테고리의 다른 글
| Word Embedding (0) | 2021.10.14 |
|---|---|
| Preprocessing (0) | 2021.10.11 |
| 자연어처리 (0) | 2021.10.05 |