◎ Word Embedding
- 단어는 discrete symbol & categorical value 형태이지만, 우리의 머릿속에서는 다르게 동작, 어휘는 계층적 의미 구조를 지니고 있으며, 이에 따라 단어 사이의 유사성을 지닌다.
- One-hot 인코딩으로 표현된 값은 유사도나 모호성을 표현할 수 없다. (Dense vector로 표현하는 것이 유리)
※ Feature Vector
- Feature(특징) : 샘플을 잘 설명하는 특징, 특징을 통해 우리는 특정 샘플을 수치화 할 수 있다.
- Feature Vector : 각 특징들을 모아서 하나의 vector로 만든 것
※ Word Embedding
- 딥러닝의 시대에 단어를 연속적인 값으로 표현하고자 하는 시도가 이어짐
- 이전에 비해 휼륭한 dense vector를 얻을 수 있게 되어 단어의 필요한 특징을 잘 표현할 수 있게 되었음
◎ Word sense
□ We need Word Sense Disambiguation (WSD)
□ Synonyms : 동의어
□ Antonyms : 반의어
□ Hypernyms & Hyponyms : 개념을 포괄하는 상위 개념이 존재하며, 계층적 구조를 지님 (동물 / 코끼리, 전화기 / 핸드폰)
■ 하지만 우리는 one-hot 인코딩을 통해 단어를 표현하므로 앞서 다룬 내용을 반영할 수 없다...
◎ WordNet
- Thesaurus(어휘분류사전, 시소러스)
- 동의어 집합(Synset) 또는 상위어(Hypernym)나 하위어(Hyponym)에 대한 정보가 잘 구축되어 있는 것이 장점
- 단어의 계층적 구조를 파악할 수 있음
- 동의어 집합(synset)을 구할 수 있음
- 단어 사이의 유사도를 계산할 수 있음
- 모든 것이 코퍼스 없이 가능
- 신조어나 사전에 등록되지 않은 단어는 오류 발생 가능

◎ Word Feature Vectors : Traditional Methods
● Data-driven Metods
- Thesaurus 기반 방식은 사전에 대해 의존도가 높으므로, 활용도가 떨어질 수 있음
- 데이터에 기반한 방식은 (데이터가 충분하다면) task에 특화된 활용이 가능
- 여전히 sparse한 vector로 표현됨, PCA를 통해 차원 축소를 하는 것도 한 방법
● TF-IDF
- 텍스트 마이닝에서 중요하게 사용
- 어떤 단어 w가 문서 d 내에서 얼마나 중요한지 나타내는 수치
- TF(Term Frequency) : 단어의 문서 내에 출현한 횟수, 숫자가 클수록 문서 내에서 중요한 단어, 하지만 'the'와 같은 단어도 TF값이 매우 클 것
- IDF(Inverse Document Frequency) : 그 단어가 출현한 문서의 숫자의 역수, 값이 클수록 'the'와 같이 일반적으로 많이 쓰이는 단어
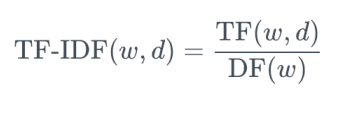
◎ Similarity Metrics
※ Manhattan Distance (L1 distance)

※ Euclidean Distance (L2 distance)

※ Infinity Norm

※ Cosine Similarity : 벡터의 방향을 중요시한다, Feature vector의 각 차원의 상대적인 크기가 중요할 때 사용

◎ Word2Vec
※ 주변(context window)에 같은 단어가 나타나는 단어일수록 비슷한 벡터 값을 가져야 한다.
+ 문장의 문맥에 따라 정해지는 것이 아님
○ Skip-gram
▷ 기본 전략 : 주변 단어를 예측하도록 하는 과정에서 적절한 단어의 임베딩(정보의 압축)을 할 수 있다. Non-linear activation func. 이 없음
▷ : 기본적인 개념은 오토인코더와 굉장히 비슷함
▷ : 쉽다, 빠르다, 비교적 정확한 벡터를 구할 수 있다. / 한데 느리다, 출현 빈도가 적은 단어일 경우 벡터가 정확하지 않다.
○ GloVe
▷ 단어 x와 윈도우 내에 함께 출현한 단어들의 출현 빈도를 맞추도록 훈련
▷ 출현 빈도가 적은 단어에 대해서는 loss의 기여도를 낮춤, 출현 빈도가 적은 단어에 대해 부정확 해시는 단점을 보완
▷ 장점 : 더 빠르다, 전체 코퍼스에 대해 각 단어 별 co-occurrence를 구한 후, regression을 수행, 출현 빈도가 적은 단어도 벡터를 비교적 정확하게 잘 구할 수 있다.
○ FastText
▷ 기존의 word2vec의 저빈도 단어에 대한 학습과 OoV에 대한 대처가 어려웠음
▷ FastText는 학습 시, 단어를 subword로 나누고, Skip-gram을 활용하여, 각 subword에 대한 embedding vector에 주변 단어의 context vector를 곱하여 더한다.
▷ 최종적으로 각 subword에 대한 embedding vector의 합이 word embedding vector가 된다.
◎ Word Embedding Equations
○ Skip-gram

○ GloVe : Turn into regression task from classification task

○ FastText

◎ Dimension Reduction Perspective
※ Autoencoders : 인코더와 디코더를 통해 압축과 해제를 실행
+ 인코더는 입력의 정보를 최대한 보존하도록 손실 압축을 수행
+ 디코더는 중간 결과물의 정보를 입력과 같아지도록 압축 해제를 수행
※ 복원을 성공적으로 하기 위해, 오토인코더는 특징을 추출하는 방법을 자동으로 학습
◎ Embedding Layer
※ 신경망에는 one-hot vector를 넣는 것이 정석, Embedding layer : Computation Efficiency (계산의 효율성을 위해 사용)
※ Embedding layer를 통해 One-hot vector를 각 task에 맞는 dense representation으로 바꿀 수 있음
※ 딥러닝의 모토는 end-to-end solution을 만드는 것
※ 단어 임베딩이 최종 목표인 경우는 거의 없음, Word2Vec의 비지도학습 특성을 활용하려는 시도는 있으나, 상용화하기엔 부족
○ Sentence Embedding
- 흔히 시도되는 방법은 문장 내 단어 임베딩 벡터들을 모두 더하는 것
- 하지만 어순을 무시한 채 평균을 구하는 것이므로 detail이 뭉개질 수 있다.
○ Context Embedding
- 단어는 문맥에 따라서 의미가 변화. 따라서 문맥에 따른 임베딩이 필요함
- 문맥을 고려하기 위해서는 주변 단어들의 쓰임새를 살펴야 한다. 이후 다룰 <텍스트 분류(RNN)>, <자연어 생성> 주제들의 기본 원리
'Data scientist > 자연어처리' 카테고리의 다른 글
| Text Classification (0) | 2021.10.15 |
|---|---|
| Preprocessing (0) | 2021.10.11 |
| 자연어처리 (0) | 2021.10.05 |