
#wannabeeeeeee the best DataScientist
Machine Learning_basic(2) 본문
728x90
◎ Deep Learning 주요 모델 1
- Neural Network는 overfitting이 심하게 일어나고 학습시간이 매우 오래 걸린다.
- 알고리즘 및 GPU의 발전은 Deep learning의 부흥을 이끈다.
- 딥러닝은 다양한 형태로 발전(CNN, RNN, AutoEncoder 등)
- 그 외 Object detection, Image Resolution, Style transfer, Colorization 등 다양한 분야로도 발전
◎ Deep Learning 주요 모델 2
1. GAN(Generative Adversarial Network) : 데이터를 만들어내는 Generator와 만들어진 데이터를 평가하는 Discriminator가 서로 대립적(Adversarial)으로 학습해가며 성능을 점차 개선해 나가는 개념




2. 강화 학습(Reinforcement Learning)
◎ 모형 적합성 평가 및 실험 설계
- 과적합을 방지하기 위해 전체 데이터를 학습 데이터, 검증 데이터, 테스트 데이터로 나누어 분석을 한다.
- 데이터 분할 -> 모형 학습 -> 모형 선택 -> 최종 성능 지표 도출
k-Fold 교차검증(k-Fold Cross Validation)
- 모형의 적합성을 보다 객관적으로 평가하기 위한 방법
- 데이터를 k개 부분으로 나눈 뒤, k번 반복하여 k개의 성능 지표를 평균하여 모형의 적합성 평가
LOOCV(Leave-One-Out Cross Validation)
- 데이터의 수가 적을 때 사용하는 교차검증 방법
- 총 n(데이터 수만큼) 개의 모델을 만든 후, 각 모델은 하나의 샘플만 제외하면서 모델을 만들고 제외한 샘플로 성능 지표를 계산한다. 그렇게 도출된 n개의 성능 지표를 평균 내어 최종 성능 지표를 도출

⑴ 전처리 : Raw 데이터를 모델링할 수 있도록 데이터를 병합 및 파생 변수 생성
⑵ 실험설계 : test데이터는 실제로 우리가 모델을 적용을 한다는 가정하에 실행하여야 한다.
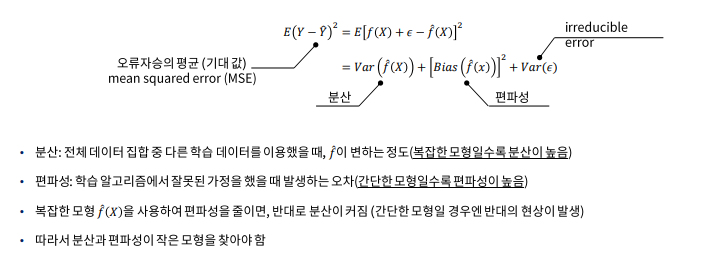
◎ 과적합(Overfitting)
- 과적합은 복잡한 모형일수록, 데이터가 적을수록 과적합이 일어나기 쉽다.
728x90
'Data scientist > Machine Learning' 카테고리의 다른 글
| 회귀분석(2)_Code (0) | 2021.08.19 |
|---|---|
| 회귀분석(1) (0) | 2021.08.19 |
| 수학적 개념 이해(2) (0) | 2021.08.19 |
| 수학적 개념 이해(1) (0) | 2021.08.19 |
| Machine Learning_basic(1) (0) | 2021.08.18 |
'Data scientist/Machine Learning' Related Articles
more



